
Анализ международных документов по управлению рисками информационной безопасности. Часть 1
Друзья, в предыдущей публикации мы рассмотрели нормативные документы по защите информации в российской кредитно-финансовой сфере, некоторые из которых ссылаются на методологии оценки и управления рисками ИБ. Вообще, если говорить с позиции бизнеса, управление информационной безопасностью является дочерним процессом более широкого процесса управления рисками: если компания после анализа и оценки всех своих бизнес-рисков делает вывод об актуальности рисков ИБ, то в игру вступает уже непосредственно защита информации как способ минимизации некоторых рисков. Управление рисками позволяет эффективно и рационально выстраивать процессы ИБ и распределять ресурсы для защиты активов компании, а оценка рисков позволяет применять целесообразные меры по их минимизации: для защиты от существенных и актуальных угроз логично будет применять более дорогостоящие решения, чем для противодействия незначительным или труднореализуемым угрозам.
Кроме этого, выстроенный процесс управления рисками ИБ позволит разработать и в случае необходимости применить чёткие планы обеспечения непрерывности деятельности и восстановления работоспособности (Business Continuity & Disaster Recovery): глубокая проработка различных рисков поможет заранее учесть, например, внезапно возникшую потребность в удаленном доступе для большого количества сотрудников, как это может произойти в случае эпидемий или коллапса транспортной системы. Итак, в этой публикации — анализ международных документов по управлению рисками информационной безопасности. Приятного чтения!

Общая концепция управления рисками ИБ
Под риском информационной безопасности, или киберриском, понимают потенциальную возможность использования уязвимостей активов конкретной угрозой для причинения ущерба организации. Под величиной риска условно понимают произведение вероятности негативного события и размера ущерба. В свою очередь под вероятностью события понимается произведение вероятности угрозы и опасности уязвимости, выраженные в качественной или количественной форме. Условно мы можем выразить это логической формулой:
ВеличинаРиска=ВероятностьСобытия*РазмерУщерба, где
ВероятностьСобытия=ВероятностьУгрозы*ВеличинаУязвимости
Существуют также условные классификации рисков: по источнику риска (например, атаки хакеров или инсайдеров, финансовые ошибки, воздействие государственных регуляторов, юридические претензии контрагентов, негативное информационное воздействие конкурентов); по цели (информационные активы, физические активы, репутация, бизнес-процессы); по продолжительности влияния (операционные, тактические, стратегические).
Цели анализа рисков ИБ таковы:
- Идентифицировать активы и оценить их ценность.
- Идентифицировать угрозы активам и уязвимости в системе защиты.
- Просчитать вероятность реализации угроз и их влияние на бизнес (англ. business impact).
- Соблюсти баланс между стоимостью возможных негативных последствий и стоимостью мер защиты, дать рекомендации руководству компании по обработке выявленных рисков.
Ущерб от реализации атаки может быть прямым или непрямым.
Прямой ущерб — это непосредственные очевидные и легко прогнозируемые потери компании, такие как утеря прав интеллектуальной собственности, разглашение секретов производства, снижение стоимости активов или их частичное или полное разрушение, судебные издержки и выплата штрафов и компенсаций и т.д.
Непрямой ущерб может означать качественные или косвенные потери.
Качественными потерями могут являться приостановка или снижение эффективности деятельности компании, потеря клиентов, снижение качества производимых товаров или оказываемых услуг. Косвенные потери — это, например, недополученная прибыль, потеря деловой репутации, дополнительно понесенные расходы. Кроме этого, в зарубежной литературе встречаются также такие понятия, как тотальный риск (англ. total risk), который присутствует, если вообще никаких мер защиты не внедряется, а также остаточный риск (англ. residual risk), который присутствует, если угрозы реализовались, несмотря на внедренные меры защиты.
Анализ рисков может быть как количественным, так и качественным.
Рассмотрим один из способов количественного анализа рисков. Основными показателями будем считать следующие величины:
ALE — annual loss expectancy, ожидаемые годовые потери, т.е. «стоимость» всех инцидентов за год.
SLE — single loss expectancy, ожидаемые разовые потери, т.е. «стоимость» одного инцидента.
EF — exposure factor, фактор открытости перед угрозой, т.е. какой процент актива разрушит угроза при её успешной реализации.
ARO — annualized rate of occurrence, среднее количество инцидентов в год в соответствии со статистическими данными.
Значение SLE вычисляется как произведение расчётной стоимости актива и значения EF, т.е. SLE=AssetValue*EF. При этом в стоимость актива следует включать и штрафные санкции за его недостаточную защиту.
Значение ALE вычисляется как произведение SLE и ARO, т.е. ALE=SLE*ARO. Значение ALE поможет проранжировать риски — риск с высоким ALE будет самым критичным. Далее рассчитанное значение ALE можно будет использовать для определения максимальной стоимости реализуемых мер защиты, поскольку, согласно общепринятому подходу, стоимость защитных мер не должна превышать стоимость актива или величину прогнозируемого ущерба, а расчетные целесообразные затраты на атаку для злоумышленника должны быть меньше, чем ожидаемая им прибыль от реализации этой атаки. Ценность мер защиты также можно определить, вычтя из расчётного значения ALE до внедрения мер защиты значение расчётного значения ALE после внедрения мер защиты, а также вычтя ежегодные затраты на реализацию этих мер. Условно записать это выражение можно следующим образом:
(Ценность мер защиты для компании) = (ALE до внедрения мер защиты) — (ALE после внедрения мер защиты) — (Ежегодные затраты на реализацию мер защиты)
Примерами качественного анализа рисков могут быть, например, метод Дельфи, в котором проводится анонимный опрос экспертов в несколько итераций до достижения консенсуса, а также мозговой штурм и прочие примеры оценки т.н. «экспертным методом».
Далее приведем краткий и неисчерпывающий список различных методологий риск-менеджмента, а самые популярные из них мы рассмотрим дальше уже подробно.
1. Фреймворк «NIST Risk Management Framework» на базе американских правительственных документов NIST (National Institute of Standards and Technology, Национального института стандартов и технологий США) включает в себя набор взаимосвязанных т.н. «специальных публикаций» (англ. Special Publication (SP), будем для простоты восприятия называть их стандартами):
1.1. Стандарт NIST SP 800-39 «Managing Information Security Risk» ( «Управление рисками информационной безопасности») предлагает трехуровневый подход к управлению рисками: организация, бизнес-процессы, информационные системы. Данный стандарт описывает методологию процесса управления рисками: определение, оценка, реагирование и мониторинг рисков.
1.2. Стандарт NIST SP 800-37 «Risk Management Framework for Information Systems and Organizations» ( «Фреймворк управления рисками для информационных систем и организаций») предлагает для обеспечения безопасности и конфиденциальности использовать подход управления жизненным циклом систем.
1.3. Стандарт NIST SP 800-30 «Guide for Conducting Risk Assessments» ( «Руководство по проведению оценки рисков») сфокусирован на ИТ, ИБ и операционных рисках. Он описывает подход к процессам подготовки и проведения оценки рисков, коммуницирования результатов оценки, а также дальнейшей поддержки процесса оценки.
1.4. Стандарт NIST SP 800-137 «Information Security Continuous Monitoring» ( «Непрерывный мониторинг информационной безопасности») описывает подход к процессу мониторинга информационных систем и ИТ-сред в целях контроля примененных мер обработки рисков ИБ и необходимости их пересмотра.
2. Стандарты Международной организации по стандартизации ISO (International Organization for Standardization):
2.1. Стандарт ISO/IEC 27005:2018 «Information technology — Security techniques — Information security risk management» («Информационная технология. Методы и средства обеспечения безопасности. Менеджмент риска информационной безопасности») входит в серию стандартов ISO 27000 и является логически взаимосвязанным с другими стандартами по ИБ из этой серии. Данный стандарт отличается фокусом на ИБ при рассмотрении процессов управления рисками.
2.2. Стандарт ISO/IEC 27102:2019 «Information security management — Guidelines for cyber-insurance» («Управление информационной безопасностью. Руководство по киберстрахованию») предлагает подходы к оценке необходимости приобретения киберстраховки как меры обработки рисков, а также к оценке и взаимодействию со страховщиком.
2.3. Серия стандартов ISO/IEC 31000:2018 описывает подход к риск-менеджменту без привязки к ИТ/ИБ. В этой серии стоит отметить стандарт ISO/IEC 31010:2019 «Risk management — Risk assessment techniques» — на данный стандарт в его отечественном варианте ГОСТ Р ИСО/МЭК 31010-2011 «Менеджмент риска. Методы оценки риска» ссылается 607-П ЦБ РФ «О требованиях к порядку обеспечения бесперебойности функционирования платежной системы, показателям бесперебойности функционирования платежной системы и методикам анализа рисков в платежной системе, включая профили рисков».
3. Методология FRAP (Facilitated Risk Analysis Process) является относительно упрощенным способом оценки рисков, с фокусом только на самых критичных активах. Качественный анализ проводится с помощью экспертной оценки.
4. Методология OCTAVE (Operationally Critical Threat, Asset, and Vulnerability Evaluation) сфокусирована на самостоятельной работе членов бизнес-подразделений. Она используется для масштабной оценки всех информационных систем и бизнес-процессов компании.
5. Стандарт AS/NZS 4360 является австралийским и новозеландским стандартом с фокусом не только на ИТ-системах, но и на бизнес-здоровье компании, т.е. предлагает более глобальный подход к управлению рисками. Отметим, что данный стандарт в настоящий момент заменен на стандарт AS/NZS ISO 31000-2009.
6. Методология FMEA (Failure Modes and Effect Analysis) предлагает проведение оценки системы с точки зрения её слабых мест для поиска ненадежных элементов.
7. Методология CRAMM (Central Computing and Telecommunications Agency Risk Analysis and Management Method) предлагает использование автоматизированных средств для управления рисками.
8. Методология FAIR (Factor Analysis of Information Risk) — проприетарный фреймворк для проведения количественного анализа рисков, предлагающий модель построения системы управления рисками на основе экономически эффективного подхода, принятия информированных решений, сравнения мер управления рисками, финансовых показателей и точных риск-моделей.
9. Концепция COSO ERM (Enterprise Risk Management) описывает пути интеграции риск-менеджмента со стратегией и финансовой эффективностью деятельности компании и акцентирует внимание на важность их взаимосвязи. В документе описаны такие компоненты управления рисками, как стратегия и постановка целей, экономическая эффективность деятельности компании, анализ и пересмотр рисков, корпоративное управление и культура, а также информация, коммуникация и отчетность.
NIST Risk Management Framework
Первым набором документов будет фреймворк управления рисками (Risk Management Framework) американского национального института стандартов и технологий (NIST). Данный институт выпускает документы по ИБ в рамках серии стандартов FIPS (Federal Information Processing Standards, Федеральные стандарты обработки информации) и рекомендаций SP (Special Publications, Специальные публикации) 800 Series. Данная серия публикаций отличается логической взаимосвязанностью, детальностью, единой терминологической базой. Среди документов, касающихся управления рисками ИБ, следует отметить публикации NIST SP 800-39, 800-37, 800-30, 800-137 и 800-53/53a.
Создание данного набора документов было следствием принятия Федерального закона США об управлении информационной безопасностью (FISMA, Federal Information Security Management Act, 2002 г.) и Федерального закона США о модернизации информационной безопасности (FISMA, Federal Information Security Modernization Act, 2014 г.). Несмотря на декларируемую «привязку» стандартов и публикаций NIST к законодательству США и обязательность их исполнения для американских государственных органов, эти документы вполне можно рассматривать и как подходящие для любой компании, стремящейся улучшить управление ИБ, вне зависимости от юрисдикции и формы собственности.
NIST SP 800-39
Итак, документ NIST SP 800-39 «Managing Information Security Risk: Organization, Mission, and Information System View» («Управление риском информационной безопасности: Уровень организации, миссии, информационной системы») предлагает вендоро-независимый, структурированный, но гибкий подход к управлению рисками ИБ в контексте операционной деятельности компании, активов, физических лиц и контрагентов. При этом риск-менеджмент должен быть целостным процессом, затрагивающим всю организацию, в которой практикуется риск-ориентированное принятие решений на всех уровнях. Управление риском определяется в данном документе как всеобъемлющий процесс, включающий в себя этапы определения (frame), оценки (assess), обработки (respond) и мониторинга (monitor) рисков. Рассмотрим эти этапы подробнее.
1. На этапе определения рисков организации следует выявить:
- предположения о рисках, т.е. идентифицировать актуальные угрозы, уязвимости, последствия, вероятность возникновения рисков;
- ограничения рисков, т.е. возможности осуществления оценки, реагирования и мониторинга;
- риск-толерантность, т.е. терпимость к рискам — приемлемые типы и уровни рисков, а также допустимый уровень неопределенности в вопросах управления рисками;
- приоритеты и возможные компромиссы, т.е. нужно приоритизировать бизнес-процессы, изучить компромиссы, на которые может пойти организация при обработке рисков, а также временные ограничения и факторы неопределенности, сопровождающие этот процесс.
- угрозы ИБ, т.е. конкретные действия, лиц или сущности, которые могут являться угрозами для самой организации или могут быть направлены на другие организации;
- внутренние и внешние уязвимости, включая организационные уязвимости в бизнес-процессах управления компанией, архитектуре ИТ-систем и т.д.;
- ущерб организации с учетом возможностей эксплуатации уязвимостей угрозами;
- вероятность возникновения ущерба.
Для обеспечения процесса оценки рисков организация предварительно определяет:
- инструменты, техники и методологии, используемые для оценки риска;
- допущения относительно оценки рисков;
- ограничения, которые могут повлиять на оценки рисков;
- роли и ответственность;
- способы сбора, обработки и передачи информации об оценке рисков в пределах организации;
- способы проведения оценки рисков в организации;
- частоту проведения оценки рисков;
- способы получения информации об угрозах (источники и методы).
- разработку возможных планов реагирования на риск;
- оценку возможных планов реагирования на риск;
- определение планов реагирования на риск, допустимых с точки зрения риск-толерантности организации;
- реализацию принятых планов реагирования на риск.
4. На этапе мониторинга рисков решаются следующие задачи:
- проверка реализации принятых планов реагирования на риск и выполнения нормативных требований ИБ;
- определение текущей эффективности мер реагирования на риски;
- определение значимых для риск-менеджмента изменений в ИТ-системах и средах, включая ландшафт угроз, уязвимости, бизнес-функции и процессы, архитектуру ИТ-инфраструктуры, взаимоотношения с поставщиками, риск-толерантность организации и т.д.
Управление рисками ведется на уровнях организации, бизнес-процессов и информационных систем, при этом следует обеспечивать взаимосвязь и обмен информацией между данными уровнями в целях непрерывного повышения эффективности осуществляемых действий и коммуникации рисков всем стейкхолдерам. На верхнем уровне (уровне организации) осуществляется принятие решений по определению рисков, что напрямую влияет на процессы, ведущиеся на нижележащих уровнях (бизнес-процессов и информационных систем), а также на финансирование этих процессов.
На уровне организации осуществляются выработка и внедрение функций управления, согласующихся с бизнес-целями организации и с нормативными требованиями: создание функции риск-менеджмента, назначение ответственных, внедрение стратегии управления рисками и определение риск-толерантности, разработка и реализация инвестиционных стратегий в ИТ и ИБ.
На уровне бизнес-процессов осуществляются определение и создание риск-ориентированных бизнес-процессов и организационной архитектуры, которая должна быть основана на сегментации, резервировании ресурсов и отсутствии единых точек отказа. Кроме того, на данном уровне осуществляется разработка архитектуры ИБ, которая обеспечит эффективное выполнение требований ИБ и внедрение всех необходимых мер и средств защиты.
На уровне информационных систем следует обеспечить выполнение решений, принятых на более высоких уровнях, а именно обеспечить управление рисками ИБ на всех этапах жизненного цикла систем: инициализации, разработки или приобретения, внедрения, использования и вывода из эксплуатации. В документе подчеркивается важность стойкости (resilience) ИТ-систем, которая является показателем жизнеспособности бизнес-функций компании.
Отметим, что в приложении «H» к рассматриваемому в документу приводится описание каждого из способов обработки рисков, перечисленных в этапе реагирования на риск. Так, указано, что в организации должна существовать как общая стратегия выбора конкретного способа обработки риска в той или иной ситуации, так и отдельные стратегии для каждого из способов обработки рисков. Указаны основные принципы выбора того или иного подхода к обработке рисков:
- принятие (acceptance) риска не должно противоречить выбранной стратегии риск-толерантности организации и её возможности нести ответственность за возможные последствия принятого риска;
- избегание (avoidance) риска является зачастую самым надежным способом обработки рисков, однако может идти вразрез с желанием компании широко применять ИТ-системы и технологии, поэтому рекомендованным подходом является целесообразный и всесторонне взвешенный выбор конкретных технологий и ИТ-сервисов;
- разделение (share) и передача (transfer) рисков — это соответственно частичное или полное разделение ответственности за последствия реализованного риска с внутренним или внешним партнером в соответствии с принятой стратегией, конечная цель которой — успешность бизнес-процессов и миссии организации;
- минимизация (или смягчение) (mitigation) рисков подразумевает применение стратегии минимизации рисков ИБ на всех трех уровнях организации и непосредственное задействование систем ИБ для смягчения возможных последствий реализации рисков. Организации следует выстраивать бизнес-процессы в соответствии с принципами защиты информации, архитектурные решения должны поддерживать возможность эффективной минимизации рисков, минимизация рисков в конкретных системах должна быть реализована с применением средств и систем защиты информации, а политики, процессы и средства ИБ должны быть достаточно универсальными и гибкими для применения их в динамичной и разнородной среде организации, с учетом непрерывно меняющегося ландшафта угроз ИБ.
NIST SP 800-37
Теперь перейдем к документу NIST SP 800-37 «Risk Management Framework for Information Systems and Organizations: A System Life Cycle Approach for Security and Privacy» («Фреймворк управления рисками для информационных систем и организаций: жизненный цикл систем для обеспечения безопасности и конфиденциальности»).
Актуальный документ имеет ревизию №2 и был обновлен в декабре 2018 с тем, чтобы учесть современный ландшафт угроз и акцентировать внимание на важности управления рисками на уровне руководителей компаний, подчеркнуть связь между фреймворком управления рисками (Risk Management Framework, RMF) и фреймворком кибербезопасности (Cybersecurity Framework, CSF), указать на важность интеграции процессов управления конфиденциальностью (англ. privacy) и управления рисками цепочек поставок (англ. supply chain risk management, SCRM), а также логически увязать список предлагаемых мер защиты (контролей, англ. controls) с документом NIST SP 800-53. Кроме этого, выполнение положений NIST SP 800-37 можно использовать при необходимости провести взаимную оценку процедур риск-менеджмента компаний в случаях, когда этим компаниям требуется обмениваться данными или ресурсами. По аналогии с NIST SP 800-39, рассматривается управление рисками на уровнях организации, миссии, информационных систем.
В NIST SP 800-37 указано, что Risk Management Framework в целом указывает на важность разработки и внедрения возможностей по обеспечению безопасности и конфиденциальности в ИТ-системах на протяжении всего жизненного цикла (англ. system development life cycle, SDLC), непрерывной поддержки ситуационной осведомленности о состоянии защиты ИТ-систем с применением процессов непрерывного мониторинга (continuous monitoring, CM) и предоставления информации руководству для принятия взвешенных риск-ориентированных решений. В RMF выделены следующие типы рисков: программный риск, риск несоответствия законодательству, финансовый риск, юридический риск, бизнес-риск, политический риск, риск безопасности и конфиденциальности (включая риск цепочки поставок), проектный риск, репутационный риск, риск безопасности жизнедеятельности, риск стратегического планирования.
Кроме этого, Risk Management Framework:
- предоставляет повторяемый процесс для риск-ориентированной защиты информации и информационных систем;
- подчеркивает важность подготовительных мероприятий для управления безопасностью и конфиденциальностью;
- обеспечивает категоризацию информации и информационных систем, а также выбора, внедрения, оценки и мониторинга средств защиты;
- предлагает использовать средства автоматизации для управления рисками и мерами защиты в режиме, близком к реальному времени, а также актуальные временные метрики для предоставления информации руководству для принятия решений;
- связывает процессы риск-менеджмента на различных уровнях и указывает на важность выбора ответственных за приятие защитных мер.
- подготовка, т.е. определение целей и их приоритизация с точки зрения организации и ИТ-систем;
- категоризация систем и информации на основе анализа возможного негативного влияния в результате потери информации (кроме негативного влияния, NIST SP 800-30 также указывает еще 3 фактора риска, учитываемых при проведении оценки риска: угрозы, уязвимости, вероятность события);
- выбор базового набора мер защиты и их уточнение (адаптация) для снижения риска до приемлемого уровня на основе оценки риска;
- внедрение мер защиты и описание того, как именно применяются меры защиты;
- оценка внедренных мер защиты для определения корректности их применения, работоспособности и продуцирования ими результатов, удовлетворяющих требованиям безопасности и конфиденциальности;
- авторизация систем или мер защиты на основе заключения о приемлемости рисков;
- непрерывный мониторинг систем и примененных мер защиты для оценки эффективности примененных мер, документирования изменений, проведения оценки рисков и анализа негативного влияния, создания отчетности по состоянию безопасности и конфиденциальности.
Перечислим далее задачи для каждого из этапов применения RMF.
Задачи этапа «Подготовка» на уровне организации включают в себя:
- определение ролей для управления рисками;
- создание стратегии управления рисками, с учетом риск-толерантности организации;
- проведение оценки рисков;
- выбор целевых значений мер защиты и/или профилей из документа Cybersecurity Framework;
- определение для ИТ-систем общих мер защиты, которые могут быть унаследованы с более высоких уровней (например, с уровня организации или бизнес-процессов)
- приоритизацию ИТ-систем;
- разработку и внедрение стратегии непрерывного мониторинга эффективности мер защиты.
- определение бизнес-функций и процессов, которые поддерживает каждая ИТ-система;
- идентификацию лиц (стейкхолдеров), заинтересованных в создании, внедрении, оценке, функционировании, поддержке, выводе из эксплуатации систем;
- определение активов, требующих защиты;
- определение границы авторизации для системы;
- выявление типов информации, обрабатываемых/передаваемых/хранимых в системе;
- идентификацию и анализ жизненного цикла всех типов информации, обрабатываемых/передаваемых/хранимых в системе;
- проведение оценки рисков на уровне ИТ-систем и обновление списка результатов оценки;
- определение требований по безопасности и конфиденциальности для систем и сред функционирования;
- определение местоположения систем в общей архитектуре компании;
- распределение точек применения требований по безопасности и конфиденциальности для систем и сред функционирования;
- формальную регистрацию ИТ-систем в соответствующих департаментах и документах.
- документирование характеристик системы;
- категоризацию системы и документирование результатов категоризации по требованиям безопасности;
- пересмотр и согласование результатов и решений по категоризации по требованиям безопасности.
- выбор мер защиты для системы и среды её функционирования;
- уточнение (адаптация) выбранных мер защиты для системы и среды её функционирования;
- распределение точек применения мер обеспечения безопасности и конфиденциальности к системе и среде её функционирования;
- документирование запланированных мер обеспечения безопасности и конфиденциальности системы и среды её функционирования в соответствующих планах;
- создание и внедрение стратегии мониторинга эффективности применяемых мер защиты, которая логически связана с общей организационной стратегией мониторинга и дополняет ее;
- пересмотр и согласование планов обеспечения безопасности и конфиденциальности системы и среды её функционирования.
- внедрение мер защиты в соответствии с планами обеспечения безопасности и конфиденциальности;
- документирование изменений в запланированные меры защиты постфактум, на основании реального результата внедрения.
- выбор оценщика или команды по оценке, соответствующих типу проводимой оценки;
- разработку, пересмотр и согласование планов по оценке внедренных мер защиты;
- проведение оценки мер защиты в соответствии с процедурами оценки, описанными в планах оценки;
- подготовку отчетов по оценке, содержащих найденные недочеты и рекомендации по их устранению;
- выполнение корректирующих действий с мерами защиты и переоценку откорректированных мер;
- подготовку плана действий на основании найденных недочетов и рекомендации из отчетов по оценке.
- сбор авторизационного пакета документов и отправку его ответственному лицу на авторизацию;
- анализ и определение риска использования системы или применения мер защиты;
- определение и внедрение предпочтительного плана действий при реагировании на выявленный риск;
- определение приемлемости риска использования системы или применения мер защиты;
- сообщение о результатах авторизации и о любом недостатке мер защиты, представляющем значительный риск для безопасности или конфиденциальности.
- мониторинг информационной системы и среды её функционирования на наличие изменений, которые влияют на состояние безопасности и конфиденциальности системы;
- оценку мер защиты в соответствии со стратегией непрерывного мониторинга;
- реагирование на риск на основе результатов непрерывного мониторинга, оценок риска, плана действий;
- обновление планов, отчетов по оценке, планов действий на основании результатов непрерывного мониторинга;
- сообщение о состоянии безопасности и конфиденциальности системы соответствующему должностному лицу в соответствии со стратегией непрерывного мониторинга;
- пересмотр состояния безопасности и конфиденциальности системы для определения приемлемости риска;
- разработку стратегии вывода системы из эксплуатации и выполнение соответствующих действий при окончании срока её службы.
NIST SP 800-30
Специальная публикация NIST SP 800-30 «Guide for Conducting Risk Assessments» («Руководство по проведению оценок риска») посвящена процедуре проведения оценки риска, которая является фундаментальным компонентом процесса управления риском в организации в соответствии с NIST SP 800-39, наряду с определением, обработкой и мониторингом рисков. Процедуры оценки рисков используются для идентификации, оценки и приоритизации рисков, порождаемых использованием информационных систем, для операционной деятельности организации, её активов и работников. Целями оценки рисков являются информирование лиц, принимающих решения, и поддержка процесса реагирования на риск путем идентификации:
- актуальных угроз как самой организации, так и опосредованно другим организациям;
- внутренних и внешних уязвимостей;
- потенциального ущерба организации с учетом возможностей эксплуатации уязвимостей угрозами;
- вероятности возникновения этого ущерба.
Процесс оценки рисков включает в себя:
- подготовку к оценке рисков;
- проведение оценки рисков;
- коммуницирование результатов оценки и передачу информации внутри организации;
- поддержание достигнутых результатов.
- описание процесса оценки риска;
- модель рисков, описывающая оцениваемые факторы риска и взаимосвязи между ними;
- способ оценки рисков (например, качественный или количественный), описывающий значения, которые могут принимать факторы риска, и то, как комбинации этих факторов могут быть обработаны;
- способ анализа (например, угрозо-центричный, ориентированный на активы или уязвимости), описывающий, как идентифицируются и анализируются комбинации факторов риска.
- угрозы;
- уязвимости;
- негативное влияние;
- вероятность;
- предварительные условия.
Угроза — это любое обстоятельство или событие, имеющее потенциал негативного влияния на бизнес-процессы или активы, сотрудников, другие организации путем осуществления несанкционированного доступа, разрушения, разглашения или модификации информации и/или отказа в обслуживании. События угроз порождаются источниками угроз. Источником угроз может быть намеренное действие, направленное на эксплуатацию уязвимости, или ненамеренное действие, в результате которого уязвимость была проэксплуатирована случайно. В целом, типы источников угроз включают в себя:
- враждебные кибератаки или физические атаки;
- человеческие ошибки;
- структурные ошибки в активах, подконтрольных организации;
- природные или техногенные аварии или катастрофы.
Рассматриваемый документ также говорит о таком понятии, как «смещение угрозы» (англ. threat shifting), под которым понимается изменение атакующими своих TTPs в зависимости от мер защиты, предпринятых компанией и выявленных атакующими. Смещение угрозы может быть осуществлено во временном домене (например, попытки атаковать в другое время или растянуть атаку во времени), в целевом домене (например, выбор менее защищенной цели), ресурсном домене (например, использование атакующими дополнительных ресурсов для взлома цели), домене планирования или метода атаки (например, использование другого хакерского инструментария или попытки атаковать иными методами). Кроме этого, подчеркивается, что атакующие зачастую предпочитают путь наименьшего сопротивления для достижения своих целей, т.е. выбирают самое слабое звено в цепи защиты.
Уязвимость — это слабость в информационной системе, процедурах обеспечения безопасности, внутренних способах защиты или в особенностях конкретной реализации/внедрения той или иной технологии или системы. Уязвимость характеризуется своей опасностью в контексте расчётной важности её исправления; при этом опасность может быть определена в зависимости от ожидаемого негативного эффекта от эксплуатации этой уязвимости. Большинство уязвимостей в информационных системах организации возникают или из-за не примененных (случайно или нарочно) мер ИБ, или примененных неверно. Важно также помнить и об эволюции угроз и самих защищаемых систем — и в тех, и в других со временем происходят изменения, которые следует учитывать при проведении переоценки рисков. Кроме уязвимостей технического характера в ИТ-системах, следует учитывать и ошибки в управлении организацией и в архитектуре систем.
Предварительное условие (англ. predisposing condition) в контексте оценки рисков — это условие, существующее в бизнес-процессе, архитектуре или ИТ-системе, влияющее (снижающее или увеличивающее) на вероятность причинения ущерба угрозой. Логическими синонимами будут термины «подверженность» (англ. susceptibility) или «открытость» (англ. exposure) риску, означающие, что уязвимость может быть проэксплуатирована угрозой для нанесения ущерба. Например, SQL-сервер потенциально подвержен уязвимости SQL-инъекции. Кроме технических предварительных условий, следует учитывать и организационные: так, местоположение офиса в низине увеличивает риск подтопления, а отсутствие коммуникации между сотрудниками при разработке ИТ-системы увеличивает риск её взлома в дальнейшем.
Вероятность возникновения (англ. likelihood of occurrence) угрозы — фактор риска, рассчитываемый на основе анализа вероятности того, что определенная уязвимость (или группа уязвимостей) может быть проэксплуатирована определенной угрозой, с учетом вероятности того, что угроза в итоге причинит реальный ущерб. Для намеренных угроз оценка вероятности возникновения обычно оценивается на основании намерений, возможностей и целей злоумышленника. Для ненамеренных угроз оценка вероятности возникновения, как правило, зависит от эмпирических и исторических данных. При этом вероятность возникновения оценивается на определенную временную перспективу — например, на следующий год или на отчетный период. В случае, если угроза практически стопроцентно будет инициирована или реализована в течение определенного временного периода, при оценке рисков следует учесть ожидаемую частоту её реализации. При оценке вероятности возникновения угрозы следует учитывать состояние управления и бизнес-процессов организации, предварительные условия, наличие и эффективность имеющихся мер защиты. Вероятность негативного влияния означает возможность того, что при реализации угрозы будет нанесен какой-либо ущерб, вне зависимости от его величины. При определении общей вероятности возникновения событий угроз можно использовать следующие три этапа:
- Оценка вероятности того, что событие угрозы будет кем-либо инициировано (в случае намеренной угрозы) или случится само (в случае ненамеренной).
- Оценка вероятности того, что возникшая угроза приведет к ущербу или нанесет вред организации, активам, сотрудникам.
- Общая вероятность рассчитывается как комбинация первых двух полученных оценок.
Уровень негативного влияния (англ. impact) события угрозы — это величина ущерба, который ожидается от несанкционированного разглашения, доступа, изменения, утери информации или недоступности информационных систем. Организации явным образом определяют:
- Процесс, используемый для определения негативного влияния.
- Предположения, используемые для определения негативного влияния.
- Источники и методы получения информации о негативном влиянии.
- Логическое обоснование, использованное для определения негативного влияния.
При оценке рисков важным фактором является степень неточности (англ. uncertainty), которая возникает из-за следующих, в общем-то, естественных ограничений, таких как невозможность с точностью спрогнозировать будущие события; недостаточные имеющиеся сведения об угрозах; неизвестные уязвимости; нераспознанные взаимозависимости.
С учетом вышесказанного, модель риска можно описать как следующую логическую структуру:
источник угрозы (с определенными характеристиками) с определенной долей вероятности инициирует событие угрозы, которое эксплуатирует уязвимость (имеющую определенную долю опасности, с учетом предварительных условий и успешного обхода защитных мер), вследствие чего создается негативное влияние (с определенной величиной риска как функции от размера ущерба и вероятности возникновения ущерба), которое порождает риск.
Документ дает также рекомендации по использованию процесса агрегирования рисков (англ. risk aggregation) в целях объединения нескольких разобщенных или низкоуровневых рисков в один более общий: например, риски отдельных ИТ-систем могут быть агрегированы в общий риск для всей поддерживаемой ими бизнес-системы. При таком объединении следует учитывать то, что некоторые риски могут реализовываться одновременно или чаще, чем это прогнозировалось. Также следует учитывать взаимосвязи между разобщенными рисками и либо объединять их, либо, наоборот, разъединять.
В NIST SP 800-30 также описаны основные способы оценки рисков: количественный (англ. quantitative), качественный (англ. qualitative) и полуколичественный (англ. semi-quantitative).
Количественный анализ оперирует конкретными цифрами (стоимостью, временем простоя, затратами и т.д.) и лучше всего подходит для проведения анализа выгод и затрат (англ. Cost–benefit analysis), однако является достаточно ресурсоёмким.
Качественный анализ применяет описательные характеристики (например, высокий, средний, низкий), что может привести к некорректным выводам ввиду малого количества возможных оценок и субъективности их выставления.
Полуколичественный способ является промежуточным вариантом, предлагающим использовать больший диапазон возможных оценок (например, по шкале от 1 до 10) для более точной оценки и анализа результатов сравнения. Применение конкретного способа оценки рисков зависит как от сферы деятельности организации (например, в банковской сфере может применяться более строгий количественный анализ), так и от стадии жизненного цикла системы (например, на начальных этапах цикла может проводиться только качественная оценка рисков, а на более зрелых — уже количественная).
Наконец, в документе также описаны три основных способа анализа факторов рисков: угрозо-центричный (англ. threat-oriented), ориентированный на активы (англ. asset/impact-oriented) или уязвимости (англ. vulnerability-oriented).
Угрозо-центричный способ сфокусирован на создании сценариев угроз и начинается с определения источников угроз и событий угроз; далее, уязвимости идентифицируются в контексте угроз, а негативное влияние связывается с намерениями злоумышленника.
Способ, ориентированный на активы, подразумевает выявление событий угроз и источников угроз, способных оказать негативное влияние на активы; во главу угла ставится потенциальный ущерб активам.
Применение способа, ориентированного на уязвимости, начинается с анализа набора предварительных условий и недостатков/слабостей, которые могут быть проэксплуатированы; далее определяются возможные события угроз и последствия эксплуатации ими найденных уязвимостей. Документ содержит рекомендации по комбинированию описанных способов анализа для получения более объективной картины угроз при оценке рисков.
Итак, как мы уже указали выше, по NIST SP 800-30 процесс оценки рисков разбивается на 4 шага:
- подготовка к оценке рисков;
- проведение оценки рисков;
- коммуницирование результатов оценки и передача информации внутри организации;
- поддержание достигнутых результатов.
1. Подготовка к оценке рисков.
В рамках подготовки к оценке рисков выполняются следующие задачи:
1.1. Идентификация цели оценки рисков: какая информация ожидается в результате оценки, какие решения будут продиктованы результатом оценки.
1.2. Идентификация области (англ. scope) оценки рисков в контексте применимости к конкретной организации, временного промежутка, сведений об архитектуре и используемых технологиях
1.3. Идентификация специфичных предположений и ограничений, с учетом которых проводится оценка рисков. В рамках этой задачи определяются предположения и ограничения в таких элементах, как источники угроз, события угроз, уязвимости, предварительные условия, вероятность возникновения, негативное влияние, риск-толерантность и уровень неточности, а также выбранный способ анализа.
1.4. Идентификация источников предварительной информации, источников угроз и уязвимостей, а также информации о негативном влиянии, которая будет использоваться в оценке рисков. В этом процессе источники информации могут быть как внутренними (такими, как отчеты по инцидентам и аудитам, журналы безопасности и результаты мониторинга), так и внешними (например, отчеты CERTов, результаты исследований и прочая релевантная общедоступная информация).
1.5. Идентификация модели рисков, способа оценки рисков и подхода к анализу, которые будут использоваться в оценке рисков.
2. Проведение оценки рисков.
В рамках оценки рисков выполняются следующие задачи:
2.1. Идентификация и характеризация актуальных источников угроз, включая возможности, намерения и цели намеренных угроз, а также возможные эффекты от ненамеренных угроз.
2.2. Идентификация потенциальных событий угроз, релевантности этих событий, а также источников угроз, которые могут инициировать события угроз.
2.3. Идентификация уязвимостей и предварительных условий, которые влияют на вероятность того, что актуальные события угроз приведут к негативному влиянию. Ее целью является определение того, насколько рассматриваемые бизнес-процессы и информационные системы уязвимы перед идентифицированными ранее источниками угроз и насколько идентифицированные события угроз действительно могут быть инициированы этими источниками угроз.
2.4. Определение вероятности того, что актуальные события угроз приведут к негативному влиянию, с учетом характеристик источников угроз, уязвимостей и предварительных условий, а также подверженности организации этим угрозам, принимая во внимание внедренные меры защиты.
2.5. Определение негативного влияния, порожденного источниками угроз, с учетом характеристик источников угроз, уязвимостей и предварительных условий, а также подверженности организации этим угрозам, принимая во внимание внедренные меры защиты.
2.6. Определение риска от реализации актуальных событий угроз, принимая во внимание уровень негативного влияния от этих событий и вероятность наступления этих событий. В Приложении «I» к данному стандарту приведена таблица I-2 для расчета уровня риска в зависимости от уровней вероятности и негативного влияния.
3. Коммуницирование результатов оценки рисков и передача информации.
В рамках коммуницирования результатов оценки рисков и передачи информации выполняются следующие задачи:
3.1. Коммуницирование результатов оценки рисков лицам, принимающим решения, для реагирования на риски.
3.2. Передача заинтересованным лицам информации, касающейся рисков, выявленных в результате оценки.
4. Поддержание достигнутых результатов.
В рамках поддержания достигнутых результатов выполняются следующие задачи:
4.1. Проведение непрерывного мониторинга факторов риска, которые влияют на риски в операционной деятельности организации, на её активы, сотрудников, другие организации. Данной задаче посвящен стандарт NIST SP 800-137, который мы рассмотрим далее.
4.2. Актуализация оценки рисков с использованием результатов процесса непрерывного мониторинга факторов риска.
Как видим, документ NIST SP 800-30 предлагает достаточно детальный подход к моделированию угроз и расчету рисков. Ценными являются также приложения к данному стандарту, содержащие примеры расчетов по каждой из подзадач оценки рисков, а также перечни возможных источников угроз, событий угроз, уязвимостей и предварительных условий.
NIST SP 800-137
Перейдем теперь к обзору документа NIST SP 800-137 «Information Security Continuous Monitoring for Federal information Systems and Organizations» («Непрерывный мониторинг информационной безопасности для федеральных информационных систем и организаций»).
Задачей построения стратегии непрерывного мониторинга информационной безопасности является оценка эффективности мер защиты и статуса безопасности систем с целью реагирования на постоянно меняющиеся вызовы и задачи в сфере информационной безопасности. Система непрерывного мониторинга ИБ помогает предоставлять ситуационную осведомленность о состоянии безопасности информационных систем компании на основании информации, собранной из различных ресурсов (таких как активы, процессы, технологии, сотрудники), а также об имеющихся возможностях по реагированию на изменения ситуации. Данная система является одной из тактик в общей стратегии управления рисками.
Как и прочие документы серии SP, в данной публикации приведен рекомендуемый процессный подход к выстраиванию системы мониторинга ИБ, состоящий из:
Не прервать связующий процесс, или Еще раз о непрерывности бизнеса и о роли управления инцидентами
Не прервать связующий процесс, или Еще раз о непрерывности бизнеса и о роли управления инцидентами
Не прервать связующий процесс, или Еще раз о непрерывности бизнеса и о роли управления инцидентами
Ежедневно в компаниях происходит множество инцидентов, приводящих к нарушению непрерывности их деятельности. Имея разный характер и последствия для бизнеса, они так или иначе приводят к прямым или косвенным финансовым потерям.

Дмитрий Моисеев
Cissp Руководитель практики систем мониторинга
событий и управления инцидентами ИБ (SIEM),
“Астерос Информационная безопасность»
Немного статистики Как показывает статистика, в среднем около 30% всех происходящих инцидентов ИБ влекут за собой либо временную недоступность критичных данных, либо прерывание бизнес-процессов компании на средний срок, и около 10% – на длительный срок. Здесь следует уточнить, что понятие «среднего» или «длительного» срока всегда индивидуально. К примеру, для банков под «средним» сроком, как правило, понимают простой около 5–6 часов, под «длительным» – прерывание критичного бизнес-процесса до нескольких дней. Если перевести в цифры, то опять же простой деятельности крупного банка в течение 1 ч (в будни) может стоить несколько сотен тысяч долларов, а сутки – несколько миллионов, простой же в течение недели, как правило, приводит к банкротству банка.
15 ноября 2013 г. в работе сотовой сети «Билайн» на севере Москвы произошел сбой. Компания сразу проинформировала абонентов о ситуации в своем Facebook и на официальном сайте. Объясняя причину неполадки, лишившей часть москвичей связи, оператор рассказал, что накануне ночью специалистами Ericsson и «Билайн» проводились плановые работы по модернизации сети, в ходе которых была выявлена некорректная работа ПО, поэтому некоторые абоненты испытывали проблемы со связью.
Среди частых причин подобных инцидентов – сбои и отказы IT и телекоммуникационной инфраструктуры, ошибки персонала, перебои электропитания и др., немалая доля приходится на инциденты информационной безопасности, приводящие к нарушению доступности IT-ресурсов или информации, необходимой для выполнения того или иного бизнес-процесса компании.
Обеспечение непрерывности бизнеса организации должно являться одной из приоритетных задач для руководства компании. Грамотное выстраивание данных процессов позволит снизить вероятность нарушений деятельности, а также минимизировать ущерб от инцидентов за счет их активного выявления и снижения времени реагирования на них.
ISO вам в помощь
Как это реализуется на практике? Международный стандарт ISO/IEC 27001 четко указывает на то, что управление непрерывностью бизнеса является одной из основных областей контроля и необходимой составляющей любой системы менеджмента ИБ. Несмотря на то что обеспечение непрерывности бизнеса выходит далеко за рамки вопросов информационной безопасности (ИБ является для них лишь одной из составляющих) и тесно связано со всеми бизнес-подразделениями компании, выстраивать соответствующие процессы в организациях часто приходится именно специалистам по ИБ.
Международный стандарт ISO 22301 описывает модель PDCA применительно к выстраиванию системы управления непрерывностью бизнеса (см. рис. 1).

Для того чтобы выстроить эффективные процессы обеспечения непрерывности бизнеса, необходимо выделить следующие основные этапы планирования непрерывности бизнеса:
- инициация проекта (получение поддержки со стороны руководства, планирование и выделение ресурсов, назначение ответственного и т.п.);
- разработка политики обеспечения непрерывности бизнеса;
- анализ деятельности компании и выявление критичных бизнес-процессов;
- разработка стратегии обеспечения непрерывности бизнеса и его восстановления;
- разработка планов обеспечения непрерывности бизнеса и восстановления IT;
- обучение персонала и проведение регулярных учений;
- регулярное тестирование планов обеспечения непрерывности бизнеса и планов восстановления IT;
- непрерывное совершенствование системы обеспечения непрерывности бизнеса.
Подходов к выстраиванию процессов обеспечения непрерывности бизнеса достаточно много, это и международные стандарты BS 25999, ISO 22301, и ведущие мировые рекомендации BCI Good Practice Guidelines. Но я бы хотел остановиться на роли процессов управления инцидентами ИБ в общей системе обеспечения непрерывности бизнеса компании, поразмышлять над тем, почему так важно их правильно интегрировать с процессами ОНБ и постоянно повышать их эффективность.
Типичный процесс реагирования на нештатные ситуации делится на следующие основные этапы:
- экстренные действия в случае чрезвычайной ситуации (Emergency Response) – то есть немедленные действия, которые необходимо предпринять в случае наступления чрезвычайной ситуации, еще до момента ее более глубокого анализа, например связь с экстренными службами, эвакуация персонала и т.п.;
- управление инцидентами (Incident Management) – ответные действия в случае обнаружения инцидента (категорирование инцидента, анализ последствий, оповещение об инциденте, эскалация информации для его обработки и т.п.);
- обеспечение непрерывности деятельности (Business continuity) – действия по обеспечению выполнения затронутых инцидентом бизнес-процессов на приемлемом уровне (минимально необходимом);
- восстановление деятельности (Recovery) – восстановление бизнес-процессов и поддерживающей их IT-инфраструктуры до нормального уровня функционирования.
Безусловно, важны все указанные этапы, однако от эффективности выполнения процессов управления инцидентами напрямую зависит масштаб ущерба от инцидентов и возможность соблюдения требований бизнеса к его восстановлению. Почему?
Управляя инцидентами – управляешь непрерывностью
В рамках разработки планов обеспечения непрерывности бизнеса и планов восстановления IT для каждого критичного бизнес-процесса и поддерживающей его IT-инфраструктуры необходимо оценивать и затем утверждать параметры восстановления – Recovery Time Objective (RTO) и Recovery Point Objective (RPO), которые должны соблюдаться и соответствовать требованиям бизнеса.
Несоблюдение этих параметров восстановления может привести к росту ущерба и сведению на нет всех усилий по управлению непрерывностью бизнеса. В связи с этим крайне важным действием является своевременная идентификация инцидента (или критичного события), который может привести к возникновению нештатной ситуации и, следовательно, нарушению выполнения критичного бизнес-процесса. Здесь важно уметь быстро проанализировать обстановку и все события, связанные с данным инцидентом, чтобы классифицировать его и выбрать план обработки.
Для такого уровня оперативности действий необходимо иметь обученный персонал, выстроенные и задокументированные процессы управления инцидентами и планы коммуникаций «на случай, если». Кроме того, в арсенале должны быть все необходимые инструментальные средства для анализа обстановки и сбора необходимой актуальной информации.
Самый SOC
Инциденты ИБ играют заметную роль во всем спектре проблем, способных привести к нарушениям операционной, производственной, управленческой деятельности. По результатам исследования Horizon Scan 2012, проведенного организацией the Business Continuity Institute (BCI) в 2012 г., наиболее актуальными угрозами для большинства компаний являются:
- сбои и отказы IT и телекоммуникационной инфраструктуры;
- утечка конфиденциальной информации;
- кибератаки (вредоносное ПО, DDoS и т.п.).
При этом угрозы ИБ наиболее актуальны для компаний финансовой сферы, телекома, здравоохранения и энергетики.
Один из подходов к выстраиванию процессов управления инцидентами ИБ – это создание центра оперативного управления ИБ компании (Security Operation Center), что является одним из инструментов, который позволяет быстро реагировать на возникающие инциденты, оперативно проводить их всесторонний анализ, эскалировать и обрабатывать инциденты согласно планам по их обработке и требованиям бизнеса, и контролировать эффективность процессов управления инцидентами ИБ.
Центр оперативного управления ИБ, как правило, является единой точкой для сбора информации о текущей ситуации в компании (с точки зрения ИБ) и ее контроля, единой точкой для эскалации инцидентов и взаимодействия с другими подразделениями компании – IT-службой, службой управления операционными рисками и др. Очень важно определить и четко регламентировать процессы и правила взаимодействия между подразделением ИБ и другими подразделениями компании и интегрировать их в планы коммуникаций в случае возникновения нештатных ситуаций.
Все этапы процесса управления инцидентами ИБ могут и должны быть полностью интегрированы и автоматизированы в рамках центра оперативного управления ИБ (см. рис. 2).

Таким образом, процессы управления инцидентами ИБ являются неотъемлемой частью комплексной системы обеспечения непрерывности бизнеса (ОНБ). Понимание важности создания системы ОНБ в целом, а также грамотное выстраивание процессов управления инцидентами и их интеграция в систему ОНБ позволят компании повысить свою стабильность за счет активного выявления проблем и потенциальных угроз, снизить ущерб от нештатных ситуаций за счет их своевременного выявления и быстрого реагирования, а также повысить свою конкурентоспособность с точки зрения надежного партнера и поставщика услуг. А создание центра оперативного управления ИБ (Security Operation Center) позволит снизить операционные затраты на процессы управления инцидентами ИБ и обеспечение непрерывности бизнеса и тем самым повысить эффективность системы ОНБ компании в целом.
Выявление инцидентов ИБ с помощью SIEM: типичные и нестандартные задачи, 2020
В инфраструктуре компаний происходит много событий, которые могут свидетельствовать о различных инцидентах информационной безопасности, таких как нарушение политик пользователями или проникновение злоумышленника в локальную сеть. Для централизованного сбора и анализа информации о событиях используют решения класса security information and event management (SIEM). Основная задача SIEM-системы — не просто собрать информацию о событиях с различных источников — сетевых устройств, приложений, журналов ОС, средств защиты, — но и автоматизировать процесс обнаружения инцидентов, а также своевременно информировать о них специалистов по безопасности. Пилотный проект позволяет продемонстрировать работу SIEM-системы в условиях, приближенных к условиям реальной корпоративной инфраструктуры. После таких проектов мы получаем много ценной информации от экспертов, поработавших с системой, и эта обратная связь позволяет совершенствовать продукт.
В этой статье мы расскажем о результатах 23 пилотных проектов по внедрению системы MaxPatrol SIEM, проведенных во второй половине 2019 — начале 2020 года 1 , и на их примере покажем, как информация из различных источников при использовании SIEM-системы позволяет выявлять инциденты ИБ в компании. Кроме того, расскажем о решении нетипичных задач с помощью SIEM-системы.
124 дня средняя длительность пилотного проекта
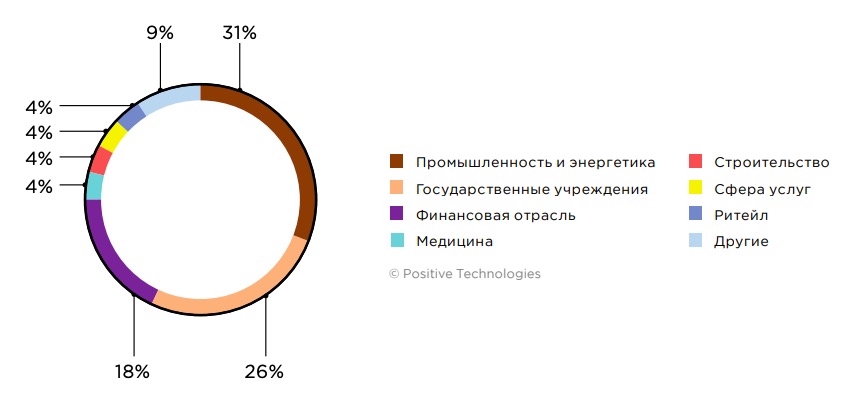
Рисунок 1. Портрет участников исследования
Как начать выявлять инциденты ИБ с помощью SIEM-системы
Для того чтобы начать выявлять инциденты ИБ в инфраструктуре компании с помощью SIEM-системы, необходимо сначала тщательно подготовиться:
- Сформулировать задачи, которые вы планируете решать с помощью SIEMсистемы. Следует учитывать особенности инфраструктуры, положения корпоративной политики ИБ, а также требования и рекомендации регулирующих организаций.
- Определить список источников, которые необходимо подключить к SIEMсистеме для решения поставленных задач.
- Если вы готовитесь к пилотному внедрению, то следует определить четкие границы пилотной зоны. Фрагмент инфраструктуры, попадающий под пилотное внедрение, должен позволить оценить работу SIEM-системы и решить поставленные задачи.
Рассмотрим подробнее, какие задачи решались с помощью SIEM-системы в ходе пилотных проектов, и разберем, какие источники следует подключать для выявления различных типов инцидентов. Также приведем примеры реальных инцидентов и кибератак, выявленных в ходе проведенных работ.
Задачи для SIEM-системы: типичные и нестандартные
SIEM-система традиционно применяется для решения проблемы накопления и оперативной обработки данных о событиях безопасности, поэтому первоочередные задачи, решаемые в рамках каждого пилотного проекта, — это сбор, хранение и обработка событий ИБ. Однако область применения SIEM-решения этим не ограничивается: с помощью SIEM-систем решаются такие важные задачи, как выявление и расследование инцидентов ИБ, инвентаризация активов, контроль защищенности информационных ресурсов. Как правило, список задач для пилотного проекта определяется на основании целей дальнейшего использования SIEM-системы в компании.
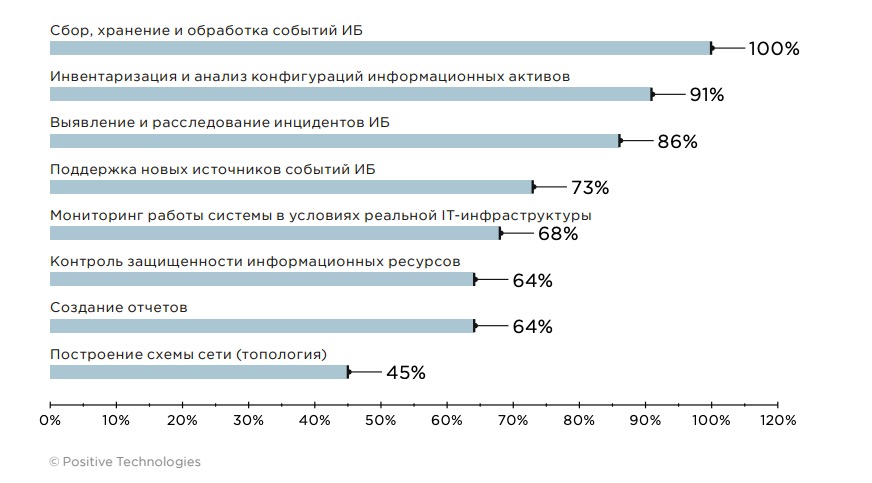
Рисунок 2. Список популярных задач для пилотного внедрения MaxPatrol SIEM (доля проектов)
Мы всегда рекомендуем формулировать такие задачи для пилотного проекта, которые важны для компании и учитывают особенности ее инфраструктуры, а также учитывают требования нормативной документации, а не такие, которые просто покажут, что SIEM-система включена и работает. Это позволяет оценить функциональность системы, проверить корректность ее конфигурации, а также определить, какие источники событий необходимо подключить для решения поставленных задач, убедиться в отсутствии «слепых зон».
В одной из компаний SIEM-система была настроена на выявление несанкционированного появления активов внутри сети, когда служба ИТ без согласования со службой ИБ вводила какие-либо новые информационные объекты. Благодаря встроенной функции инвентаризации сети появилась возможность в реальном времени детектировать события в контурах разработки и стандартизировать процесс DevOps.

Рисунок 3. Примеры нестандартных задач, решенных в рамках пилотного внедрения SIEM-системы
Источники для сбора событий
Поиск инцидентов начинается с подключения источников, которые генерируют разнородные события. Для получения наиболее полного представления о том, что происходит в инфраструктуре компании, рекомендуется подключать все имеющиеся источники IT-событий и событий ИБ.
IT-источники — общесистемное прикладное программное и аппаратное обеспечение, порождающее IT-события. IT-источники сообщают о тех или иных явлениях в автоматизированной системе без оценки уровня их защищенности (без оценки — «хорошо» или «плохо»). Примеры: журналы серверов и рабочих станций (для контроля доступа, обеспечения непрерывности, соблюдения политик информационной безопасности), сетевое оборудование (контроль изменений конфигураций и доступа к устройствам).
Источники событий ИБ — специализированное программное и аппаратное обеспечение для информационной безопасности, порождающее события ИБ. Такие источники обладают дополнительными внешними знаниями о том, как трактовать те или иные события с точки зрения безопасности (является ли наблюдаемое явление «хорошим» или «плохим»). Примеры источников событий ИБ: IDS/IPS (для сбора данных о сетевых атаках), средства антивирусной защиты (обнаружение вредоносных программ).
В рамках пилотных проектов внедрение SIEM-системы производится на тестовую площадку, имитирующую фрагмент реальной инфраструктуры компании, либо в выделенную пилотную зону, включающую в себя ряд источников.
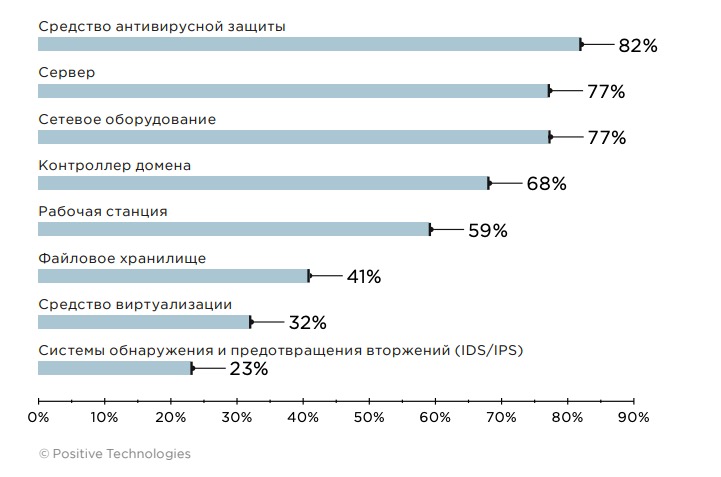
Рисунок 4. Наиболее часто подключаемые источники событий (доля проектов)
Для сбора наиболее полных данных со всех источников SIEM-система должна уметь взаимодействовать с широким спектром сетевых протоколов и технологий сетевого взаимодействия: syslog, WMI, RPC, Telnet, SSH, ODBC и другими. Например, для получения сообщений из системных журналов и журналов безопасности Windows (WinEventLog, WindowsAudit) на серверах и рабочих станциях используется протокол syslog. Так в SIEM-систему попадает информация о событиях, определенных политиками аудита Windows (таких как вход в систему, доступ к объектам, изменение привилегий). WMI позволяет собирать информацию с Windows-устройств о таких событиях, как создание, изменение или удаление файлов с определенным расширением; подключение физических устройств; запуск служб в ОС. Также рекомендуется дополнительно использовать инструмент расширенного аудита — Sysmon, поскольку в журналы аудита безопасности Windows попадает не вся информация. Sysmon отслеживает изменения в ветках реестра, видит, когда злоумышленник пытается получить хеш-значения паролей пользователей, а также позволяет отследить вредоносную активность внутри сети, получить информацию об источнике, включая хеш-значение файла, породившего процесс.
Не все инциденты можно выявить, основываясь на данных, полученных с серверов и рабочих станций. Для обнаружения атак в сетевом трафике (например, при использовании злоумышленником туннелей для передачи вредоносного кода или атаки DCSync) рекомендуется дополнить решение класса SIEM системой анализа сетевого трафика (NTA/NDR).
Ниже представлен список основных событий ИБ, выявляемых с помощью SIEM-системы, и соответствующих им источников.
- Прокси-серверы с контролем контента
- Средства защиты веб-трафика
- Средства защиты почты
- Средства защиты конечных узлов со встроенными модулями контроля веб-ресурсов и электронной почты
- Межсетевые экраны
- Средства обнаружения и предотвращения вторжений
- Межсетевые экраны
- Системы обнаружения и предотвращения вторжений
- Системы выявления и блокировки сетевых DoS-атак
- Средства обнаружения и предотвращения вторжений
- Средства обнаружения и предотвращея вторжений
- Сканеры уязвимостей и средства аудита
- Антивирусные средства защиты
- Антивирусные средства защиты
- Средства обнаружения и предотвращения вторжений
- Сканеры уязвимостей
- Системы предотвращения утечек данных
- Межсетевые экраны нового поколения (NGFW)
- Системы предотвращения течек данных
- Системы класса User and Entity Behavior Analytics
Выявленные инциденты ИБ
В рамках пилотных проектов для демонстрации возможностей SIEM-системы часто выполняется моделирование условий, которые приводят к регистрации киберинцидента. Однако, помимо смоделированных, в 100% проектов, вошедших в выборку, MaxPatrol SIEM зафиксировал еще и реальные инциденты ИБ. Во время пилотных проектов были выявлены события ИБ, свидетельствующие о потенциальных кибератаках, заражении вредоносным ПО, нарушении политик ИБ, а также об отклонениях в поведении пользователей.
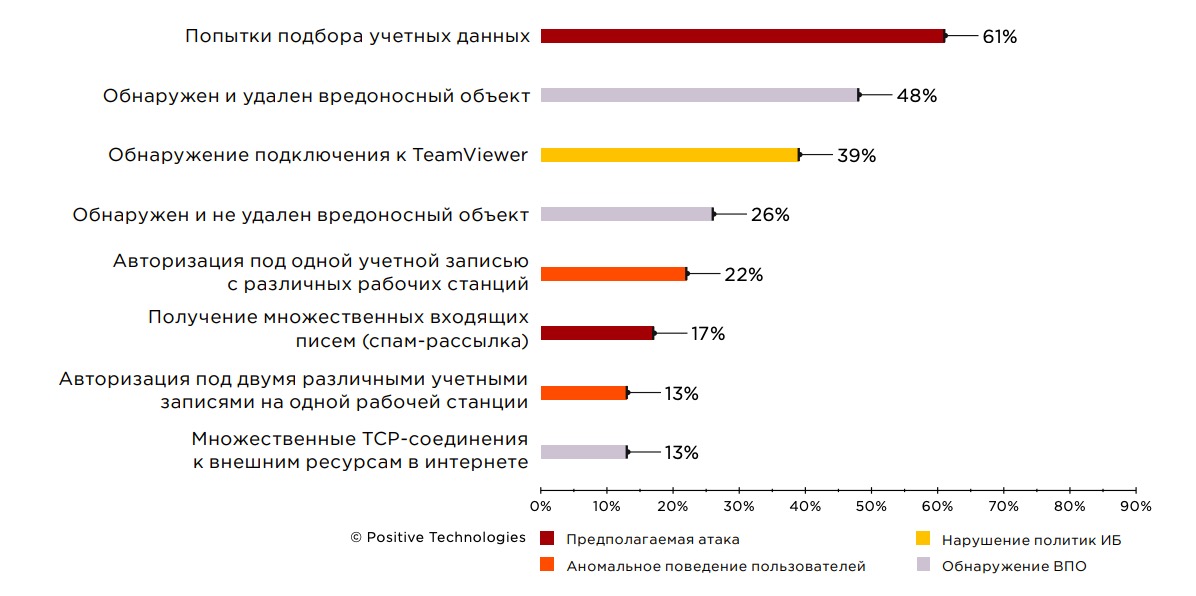
Рисунок 5. Наиболее часто выявляемые инциденты ИБ (доля проектов)
Предполагаемая атака
Специалисты Positive Technologies в ходе работ по тестированию на проникновение часто выявляют в инфраструктуре заказчика следы кибератак. Это говорит о том, что либо атака осталась незамеченной специалистами по ИБ, либо при расследовании инцидента не удалось выявить все скомпрометированные узлы, а значит, и полностью устранить последствия. Причиной может быть как отсутствие современных технических средств для выявления атак, так и недостаточный объем данных, собираемых с источников событий, и следовательно, невозможность детально отслеживать все происходящие события в инфраструктуре компании.
Во время пилотных проектов были выявлены события, которые свидетельствуют о потенциальных атаках. Многие из этих событий связаны, в частности, с получением злоумышленниками информации о скомпрометированной системе и внутренней сети: после проникновения во внутреннюю сеть жертвы преступникам требуется определить, где в инфраструктуре они находятся, принять решение о дальнейших действиях, получить учетные данные пользователей для подключения к серверам и рабочим станциям. Своевременное обнаружение этих событий может помочь специалистам по ИБ остановить кибератаку на ранней стадии и минимизировать ущерб.
К примеру, в одном из пилотных проектов был обнаружен запрос сеансового билета Kerberos для несуществующего пользователя. Подобные события могут свидетельствовать об ошибочной настройке сервиса (например, учетная запись для запуска службы была удалена, но сама служба продолжает работать) или о попытке перечисления существующих пользователей.
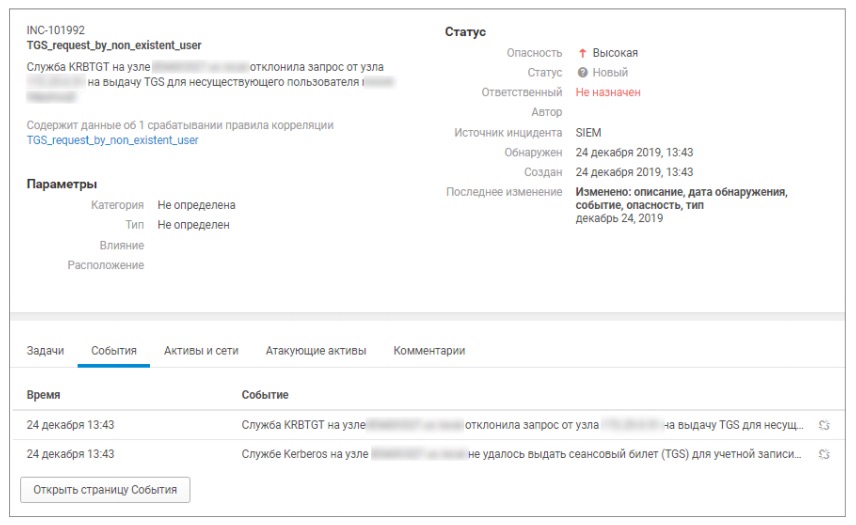
Рисунок 6. Инцидент «Обнаружение сеансового билета Kerberos для несуществующего пользователя»
В ходе атак на контроллер домена, в котором используется аутентификация по протоколу Kerberos, злоумышленники могут прибегнуть к атаке Kerberoasting. Любой аутентифицированный в домене пользователь может запросить Kerberos-билет для доступа к сервису (Ticket Granting Service, TGS). Билет TGS зашифрован NT-хешем пароля учетной записи, от имени которой запущен целевой сервис. Злоумышленник, получив значение TGS-REP, может его расшифровать, подобрав пароль от ассоциированной с сервисом учетной записи, который зачастую является простым или словарным. В ходе пилотных проектов в ряде компаний были выявлены подобные атаки.
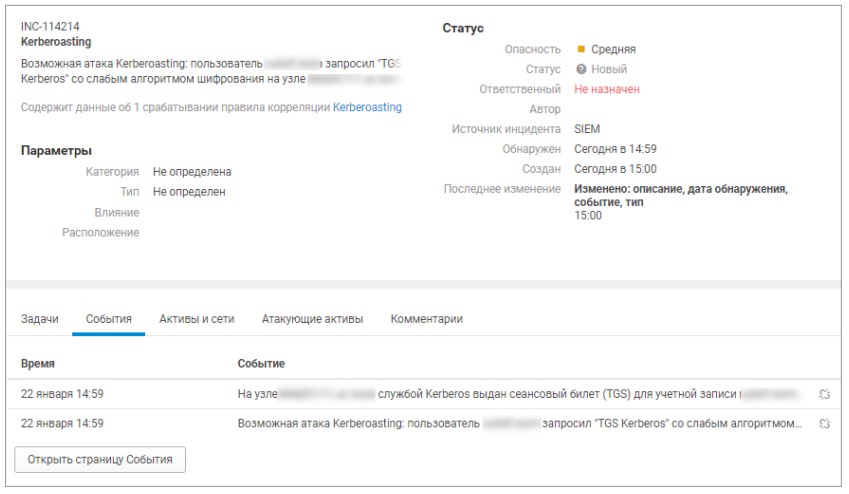
Рисунок 7. Инцидент «Атака Kerberoasting»
Перечисление существующих пользователей через запрос сеансового билета Kerberos, а также Kerberoasting злоумышленники применяют в атаках с использованием тактик «Разведка» (Discovery) и «Получение учетных данных» (Credential Access) по модели MITRE ATT&CK. SIEM-система, обладающая правилами детектирования популярных техник атак, сумеет обнаружить активность злоумышленников еще во время их попыток получить список учетных записей домена и перечень установленных приложений и служб.
В одной компании была выявлена активность злоумышленника, преодолевшего сетевой периметр с помощью фишингового письма. Вредоносное ПО начало собирать информацию о сети. SIEM-система зафиксировала, что на активе пользовательской группы (бухгалтерия) выполняются административные команды, связанные со сбором информации о домене. Таким образом с помощью SIEM-системы был выявлен факт компрометации с использованием фишинга, который пропустило другое средство защиты.
SIEM-система помогает в выявлении и других типов атак. Так, во время проведения одного из пилотных проектов была своевременно обнаружена DDoS-атака. После анализа внешних адресов, с которых обращались злоумышленники, эти адреса были заблокированы на корпоративном межсетевом экране.

Рисунок 8. Выявление DDoS-атаки с помощью MaxPatrol SIEM
В ряде пилотных проектов выполнялся ретроспективный анализ событий ИБ для выявления атак и фактов компрометации объектов инфраструктуры компании, пропущенных или неверно приоритизированных при реализации штатных мер защиты. Так, например, удалось выявить и пресечь целенаправленную атаку на ресурсы одной компании, которая длилась не менее 8 лет. По результатам анализа журналов регистрации событий SIEM-системы были выявлены следы действий злоумышленников на 195 узлах контролируемой инфраструктуры. Причем, как выяснилось во время расследования, преступники были активны на протяжении всех этих лет, а именно использовали вредоносное ПО:
- для связи с командным сервером,
- удаленного исполнения команд,
- исследования скомпрометированной инфраструктуры,
- извлечения учетных данных пользователей на узлах,
- сжатия данных в архивы,
- передачи файлов на командный сервер и приема с него.
В минимальные сроки были заблокированы командные серверы злоумышленников и ликвидировано их присутствие в инфраструктуре. В ходе расследования специалисты Positive Technologies установили принадлежность атакующих к группировке TaskMasters.
Обнаружение вредоносного ПО
Каждый пятый инцидент, выявляемый в ходе пилотных проектов, связан с обнаружением вредоносного ПО. Причем большинство из них (порядка 85%) связаны с фишинговыми рассылками. Согласно нашему исследованию APT-группировок, атаковавших компании по всему миру, 90% группировок начинают атаки именно с целенаправленных фишинговых рассылок по электронной почте.
В одном из пилотных проектов было зафиксировано большое количество вредоносных писем, в частности содержащих Trojan-Banker.RTM, отправленных сотрудникам компании с 592 различных IP-адресов. Операторов этого вредоносного ПО в основном интересуют корпоративные банковские счета, поэтому фишинговые письма адресуют бухгалтерам и финансистам, имитируя переписку с финансовыми структурами. Темой такого письма может быть, например, «Заявка на возврат», «Пакет документов за прошлый месяц» или «Паспортные данные сотрудников».
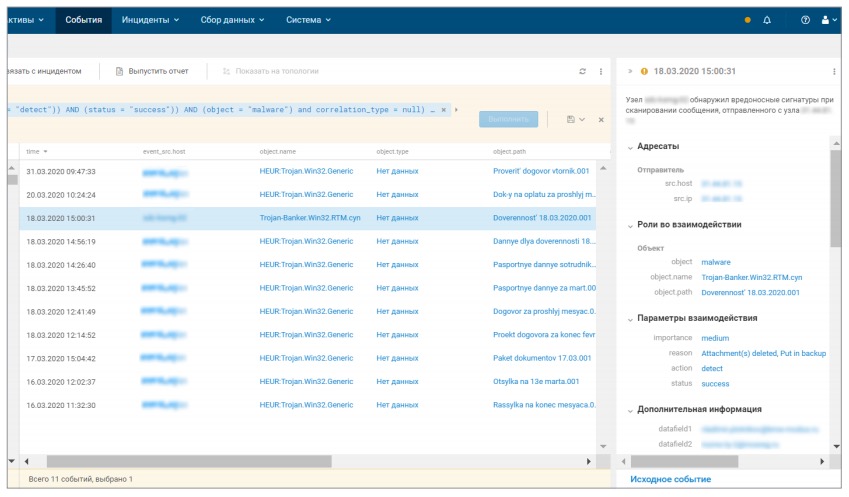
Рисунок 9. Выявление фишинговых рассылок с помощью MaxPatrol SIEM
Аномальное поведение пользователей
В исследовании, посвященном результатам работ по внутреннему тестированию на проникновение, мы говорили, что методы атак во внутренней сети основаны не только на эксплуатации уязвимостей ПО, но и на использовании архитектурных особенностей ОС и механизмов аутентификации, а также на выполнении легитимных действий, предусмотренных функциональностью системы. Легитимные действия, которые позволяют развить вектор атаки, составляют почти половину от всех действий пентестеров. Такие действия иногда сложно отличить от повседневной деятельности пользователей или администраторов, но они могут указывать на скрытое присутствие злоумышленников. Поэтому аномалии в поведении пользователей должны служить поводом для более подробного изучения событий. Примеры событий, на которые стоит обратить внимание сотрудникам службы ИБ, — это попытки выгрузки списков локальных групп или пользователей, создание нового аккаунта сразу после авторизации. В нескольких пилотных проектах SIEM-система фиксировала использование одной учетной записи на нескольких рабочих станциях, что могло означать компрометацию учетных данных. Еще одним признаком потенциальной компрометации учетных данных является работа сотрудника в ночное время.

Рисунок 10. Пример инцидента «Работа в ночное время»
Нарушение политик ИБ
Еще одна категория инцидентов — это нарушения политик ИБ. Речь идет о выявлении фактов несоответствия требованиям нормативных документов, таких как PCI DSS, приказ ФСТЭК № 21, а также корпоративным политикам ИБ. Правила, устанавливаемые этими документами, направлены на обеспечение приемлемого уровня защищенности компании. Однако пользователи не всегда строго соблюдают все требования. В половине компаний в ходе пилотных проектов были выявлены нарушения политик ИБ. Так, например, в 39% пилотных проектов были зафиксированы случаи работы программ для удаленного управления компьютером. Эти события могут быть легитимными, например когда инженер технической поддержки удаленно подключается для настройки сервера, а могут указывать на получение доступа злоумышленниками (техника атаки Remote Access Software). Как правило, компаниям рекомендуется ограничить список узлов, на которых может использоваться ПО для удаленного доступа.
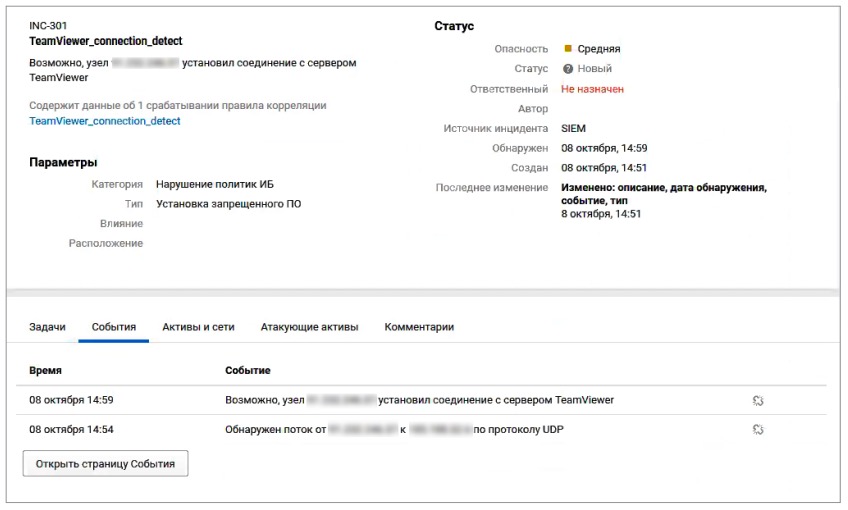
Рисунок 11. Инцидент «Выявление работы TeamViewer»
SIEM-система может применяться для проверки выполнения организационных распоряжений в части ИБ. Так, в одной из компаний было необходимо отказаться от определенного ПО, и с помощью SIEM-системы удалось собрать информацию о его использовании. Другой пример — использование решения класса SIEM в ряде организаций для проверки выполнения предписаний по смене паролей.
Заключение
Во всех компаниях происходят инциденты ИБ: выявляются использование вредоносного ПО, события, которые могут свидетельствовать о кибератаке или нарушении политик ИБ. Работы по тестированию на проникновение, выполняемые экспертами Positive Technologies, подтверждают, что в компаниях нередко выявляются следы более ранних атак хакеров, которые не были вовремя замечены службой ИБ. Для обнаружения атак на ранней стадии необходимо знать обо всем, что происходит в инфраструктуре компании. Для этого нужно собирать как можно больше информации о событиях, ведь чем полнее ведется сбор событий и чем больше источников подключено, тем больше шансов своевременно выявить подозрительную активность, принять меры по пресечению атаки и минимизировать негативные последствия.
Большой объем регистрируемых данных требует автоматизированной обработки с помощью таких решений, как SIEM. SIEM-система использует корреляцию, чтобы связывать вместе собранные данные, выявлять шаблоны, указывающие на инцидент. Опыт специалистов экспертного центра безопасности Positive Technologies показывает, что правила корреляции дают отправную точку для обнаружения большинства кибератак 2 , в том числе сложных многоступенчатых APT-атак, а также служат основой для расследования инцидентов. Если дополнительно используется система глубокого анализа трафика (решения класса NTA/NDR), то это позволяет отследить подозрительную активность не только на узлах, но и в сетевом трафике. Стоит принять во внимание, что к расследованию инцидентов следует привлекать квалифицированных экспертов, которые сумеют полностью восстановить цепочку атаки.
Источник https://habr.com/ru/post/495236/
Источник https://lib.itsec.ru/articles2/control/ne-prervat-svyazuyuschiy-protsess—ili-esche-raz-o-nepreryvnosti-biznesa-i-o-roli-upravleniya-intsidentami
Источник https://www.ptsecurity.com/ru-ru/research/analytics/incidents-siem-2020/




